What we're doing better and what's next.
👋 Happy leap day! It's been awhile.
A year ago, I shared my thoughts on rethinking our use of GraphQL in Bidx UI. That post came after a week of brainstorming during my downtime, with the hope of sparking some interest in the team and allow for a bit of codebase cleanup. I definitely got what I wished for.
That week of casual brainstorming turned into a yearlong project to not only establish some best practices but also to refactor all of our GQL related code. After I made peace with myself I worked out a plan and with the help of the entire team we completed this major effort.
Refactoring the frontend was a big challenge and a big responsibility but also a big success. We now have a consistent, structured "data layer" throughout the app. It's much easier to maintain, with data traveling from API call to display more transparently. What’s more, despite a year of considerations it remains pretty similar to the plan that we established at the start.
I'd like to revisit those original concepts: the challenges they aimed to address, their validation throughout the project, and the benefits they continue to provide us.
Redundancy and Complexity
Our old implementation was built as GraphQL was being introduced to the project; it was a learn-as-you-go kind of solution by necessity. Our code was complex because it was inconsistent in key ways.
On the one hand, some types of data were stored in one spot and shared between every page that needed them. This data could get unwieldy and modifying it could have unforeseen consequences in random places. This is the "hidden complexity" I wrote about last year -- data being transformed in various places before being stored in unexpected ways. It made it hard to trace the data from API call to elements on the page. Compare the logic for roughly the same data before and after rework:
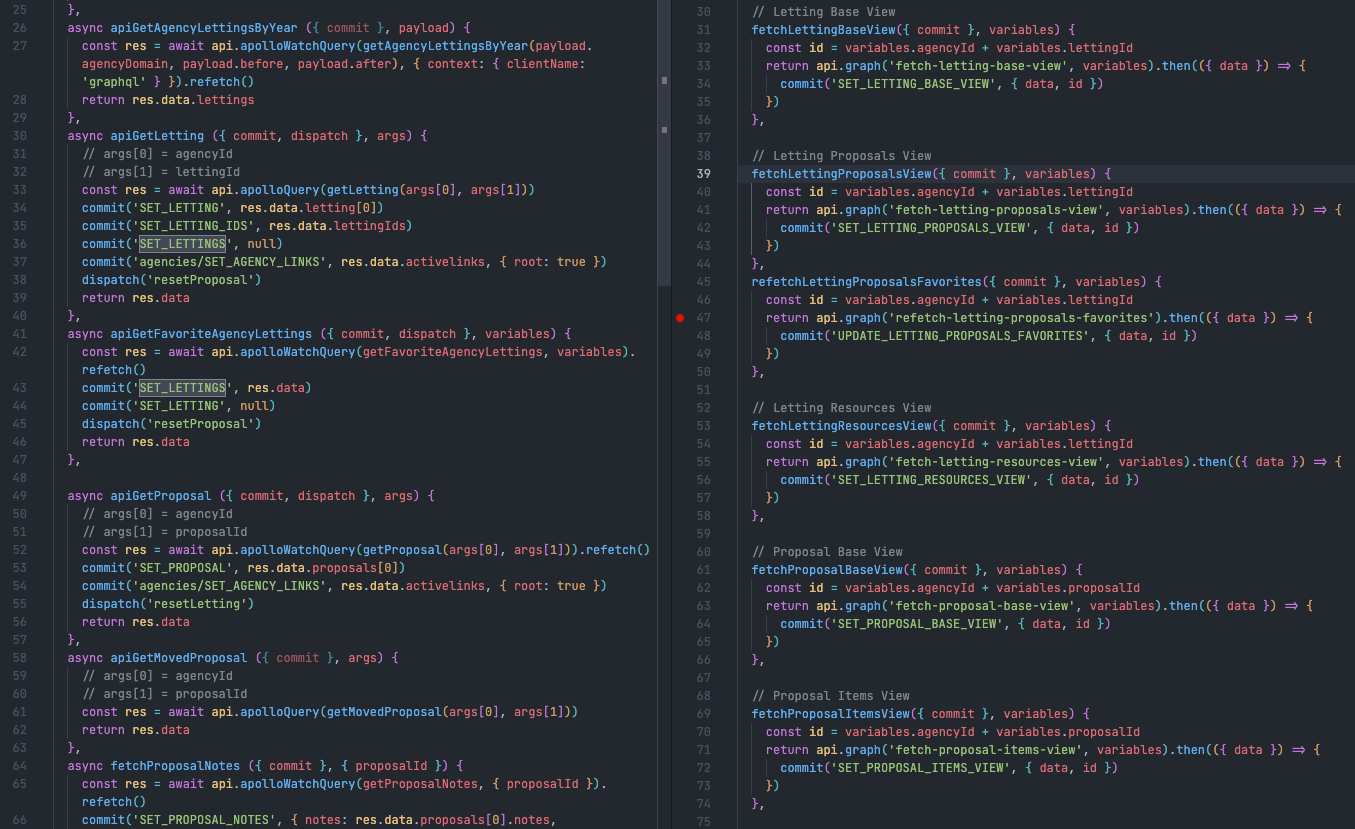
At the same time though, this created a lot of redundancy. We may only have needed to know a user's address on a couple of pages, but that data was fetched on every page load all over the app. This may sound like an obvious issue but it's the result of a sound idea: have one API call for each model in the schema, and reuse it wherever you need something from that model. This makes sense coming from a REST API, but with GraphQL that's leaving a lot of utility on the table.
So in a way we had the worst of both worlds: code was more complex than necessary and yet redundant in ways it shouldn't be. We wanted to do better and needed to go about it carefully.
Rules and Exceptions
We looked to existing frontend libraries for GraphQL to identify good practices and strategies. In the end the best resources for this project came from Apollo, who provide a best practices guide for their client library and VueJS themselves who maintain integration with Apollo. The result of this research was a set of simple conventions to guide the rework, which boil down to just a few rules:
- Follow a simple naming scheme for all data operations
- Create one API call for each page and fetch all the page's data in it
- Store the data in a corresponding place which the main view component retrieves
- Don't modify the data "in transit", create reusable functions which get applied on the page
The result is that most of the data logic looks like this:
// workspace/actions.js
fetchDashboardView({ commit }, params) {
return api.graph('fetch-dashboard-view', params).then(({ data }) => {
commit('SET_DASHBOARD_VIEW', data)
})
},
// workspace/mutations.js
SET_DASHBOARD_VIEW(state, data) {
state.dashboardView = data
},
// dashboard-view.vue
const data = computed(() => store.state.workspace.dashboardView)
Simple as can be! Our strategy is to start from simple rules and carve out exceptions only as needed, don't optimize prematurely. There are places where our data get's a little more complicated, such as in the lettings module where we want to cache data or re-fetch some data separately. Even though that deviates from the rules, if those exceptions are written in an obvious and predictable way then they remain easy to maintain. If exceptions are created with care, then they simply become rules once you employ them a few times.
The biggest exception is data needed across the entire app, which may need to be re-fetched or cached on any and all pages. Because this deviates so far from the above rules, it required some more thorough design and documentation, namely the diagram below.
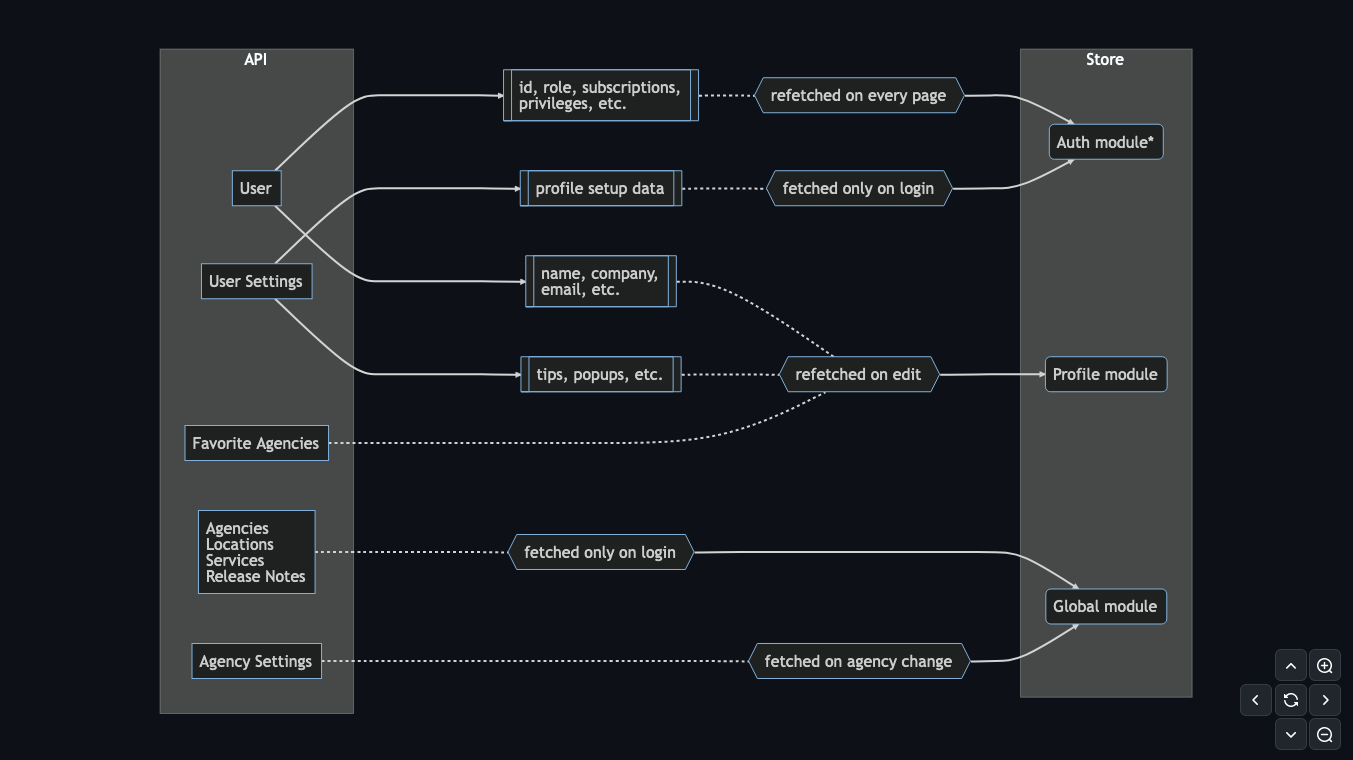
This was well worth the extra effort, where previously about 100 user properties were fetched on every page load only 13 are queried now, with another 20 cached once and re-fetched as needed.
What's next
Bidx is in a healthy place right now; we won't need to make big changes like this for a long while and we can build out new pages much quicker than before. Our new rules are just rigid enough to create that velocity but they remain flexible as requirements change (which they always do).
What's more though, I think we have a better understanding of GraphQL and are positioned to reach for more of its tools as needed. That makes working together with the backend team easier and more productive, and it just makes us better engineers. This effort was a big win but we're not resting on our laurels, the next big project is calling us 🏃🏃🏃💨
← Back to blog